React — одна из самых влиятельных библиотек в мире фронтенд-разработки. За последние годы она прошла путь от экспериментального инструмента до зрелой платформы, поддерживающей миллионы приложений по всему миру. Рассмотрим ключевые этапы её развития, включая последние обновления, связанные с выходом версии 19.1.0 (28 марта 2025 года).
Начало пути: создание и первые шаги (2011–2013)
Идея React родилась внутри Facebook в 2011 году, когда разработчики столкнулись с проблемами производительности при работе с DOM. Вместо традиционного подхода к обновлению интерфейсов было предложено использовать виртуальный DOM — легковесное представление реального дерева элементов, которое позволяет минимизировать дорогостоящие операции перерисовки.
Проект изначально назывался FaxJS, но вскоре получил название React. Его публичный релиз состоялся в мае 2013 года, когда Facebook официально открыл исходники, сделав его доступным для всего сообщества.
Стабилизация и развитие: 2013–2015
На этом этапе React активно развивался. Появились такие важные концепции, как компоненты, однонаправленный поток данных и JSX — синтаксическое расширение, упрощающее создание UI.
Версии 0.x были экспериментальными, но уже тогда стало ясно, что React предлагает нечто новое и мощное. К 2015 году вышла React 0.14, где впервые был разделен API для работы с веб-интерфейсами (react-dom) и самой библиотекой (react), что позволило использовать React за пределами традиционного веба — например, в мобильной разработке через React Native.
Современные изменения: хуки, Concurrent Mode и React 18
Ключевой поворот в истории React произошел с выпуском React 16.8 в 2019 году, который внёс долгожданный функционал — хуки (Hooks). Теперь работа с состоянием и жизненным циклом компонентов стала проще и понятнее без необходимости использования классов.
В 2022 году вышла React 18, которая представила Concurrent Mode — набор возможностей, позволяющих библиотеке более гибко управлять задачами, выполняя их асинхронно и приоритезированно. Это значительно повысило отзывчивость пользовательского интерфейса и оптимизировало производительность приложений.
React 19: новый этап эволюции (2025)
С выходом React 19.1.0 в марте 2025 года, библиотека продолжает совершенствоваться, адаптируясь к современным требованиям веб-разработки. Вот основные изменения и улучшения, которые были внедрены:
 Улучшенная поддержка асинхронных действий
Улучшенная поддержка асинхронных действий
React 19 предоставляет более гибкий способ управления асинхронными операциями с помощью новых API, таких как useTransition и useDeferredValue, теперь они стали ещё мощнее и проще в использовании.
🧠 Лучшая интеграция с AI-инструментами
Благодаря модульной архитектуре, React 19 предлагает встроенную поддержку генерации кода на основе описаний, что делает его совместимым с различными AI-помощниками, ускоряя процесс разработки.
 Оптимизация сборки и производительности
Оптимизация сборки и производительности
Теперь React работает ещё быстрее благодаря внутренним оптимизациям, уменьшению размера бандла и улучшенному алгоритму сравнения изменений в Virtual DOM.
 ️ Безопасность и типизация
️ Безопасность и типизация
Повышенный уровень безопасности и строгая проверка типов на уровне библиотеки позволили снизить количество runtime-ошибок и повысить надежность приложений.
 Поддержка новых экосистемных инструментов
Поддержка новых экосистемных инструментов
React 19 лучше интегрируется с такими технологиями, как Server Components, Streaming SSR, Turbopack, а также улучшена совместимость с TypeScript по умолчанию.
Заключение
С момента своего появления в 2013 году, React стал не просто библиотекой для создания интерфейсов, а полноценной платформой, которая динамично развивается и задаёт тренды в мире веб-технологий. Версия 19.1.0 знаменует собой очередной шаг вперёд, объединяя мощные возможности, безопасность и высокую производительность.
 Лагов почти нет, пишут, что можно доверять бизнесу, науке и разработке.
Лагов почти нет, пишут, что можно доверять бизнесу, науке и разработке.
 ️ Собрал всё лучшее в одном:
️ Собрал всё лучшее в одном: Загружай документы — PDF, Word, PowerPoint, изображения, Markdown, Python-файлы — агент всё прочитает и поймёт
Загружай документы — PDF, Word, PowerPoint, изображения, Markdown, Python-файлы — агент всё прочитает и поймёт ️ Генерация высококачественных изображений (VHQ) прямо в чате
️ Генерация высококачественных изображений (VHQ) прямо в чате Интеллектуальный веб-поиск и анализ данных в реальном времени
Интеллектуальный веб-поиск и анализ данных в реальном времени Глубокий research: агенты сами ищут, анализируют, делают выводы
Глубокий research: агенты сами ищут, анализируют, делают выводы DEX-аналитика и автоматизация торговли в DeFi (поддержка Solana RPC)
DEX-аналитика и автоматизация торговли в DeFi (поддержка Solana RPC) Создавай сеть агентов: один отвечает за поддержку, другой — за аналитику, третий — за торговлю
Создавай сеть агентов: один отвечает за поддержку, другой — за аналитику, третий — за торговлю Три режима работы:
Три режима работы: Идеи для использования:
Идеи для использования: GitHub:
GitHub: 

 Что известно на сегодня
Что известно на сегодня ️ WhatsApp: реальная угроза?
️ WhatsApp: реальная угроза? Что это значит для пользователей?
Что это значит для пользователей? Выводы
Выводы Ваше мнение
Ваше мнение Основные улучшения
Основные улучшения
 Кому подойдёт этот стандарт?
Кому подойдёт этот стандарт? Код валидации должен быть таким же чистым, как и код приложения.
Код валидации должен быть таким же чистым, как и код приложения.
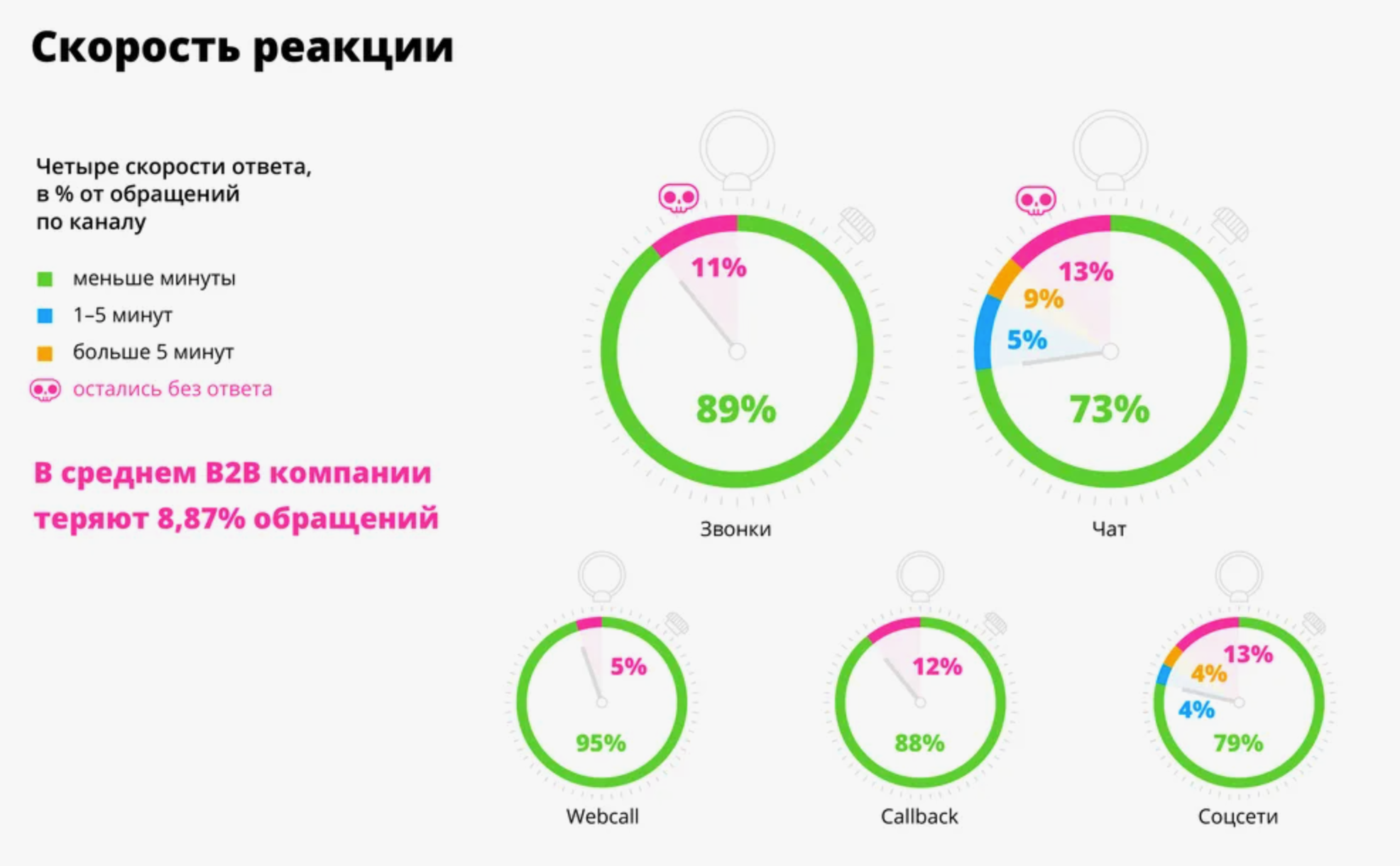
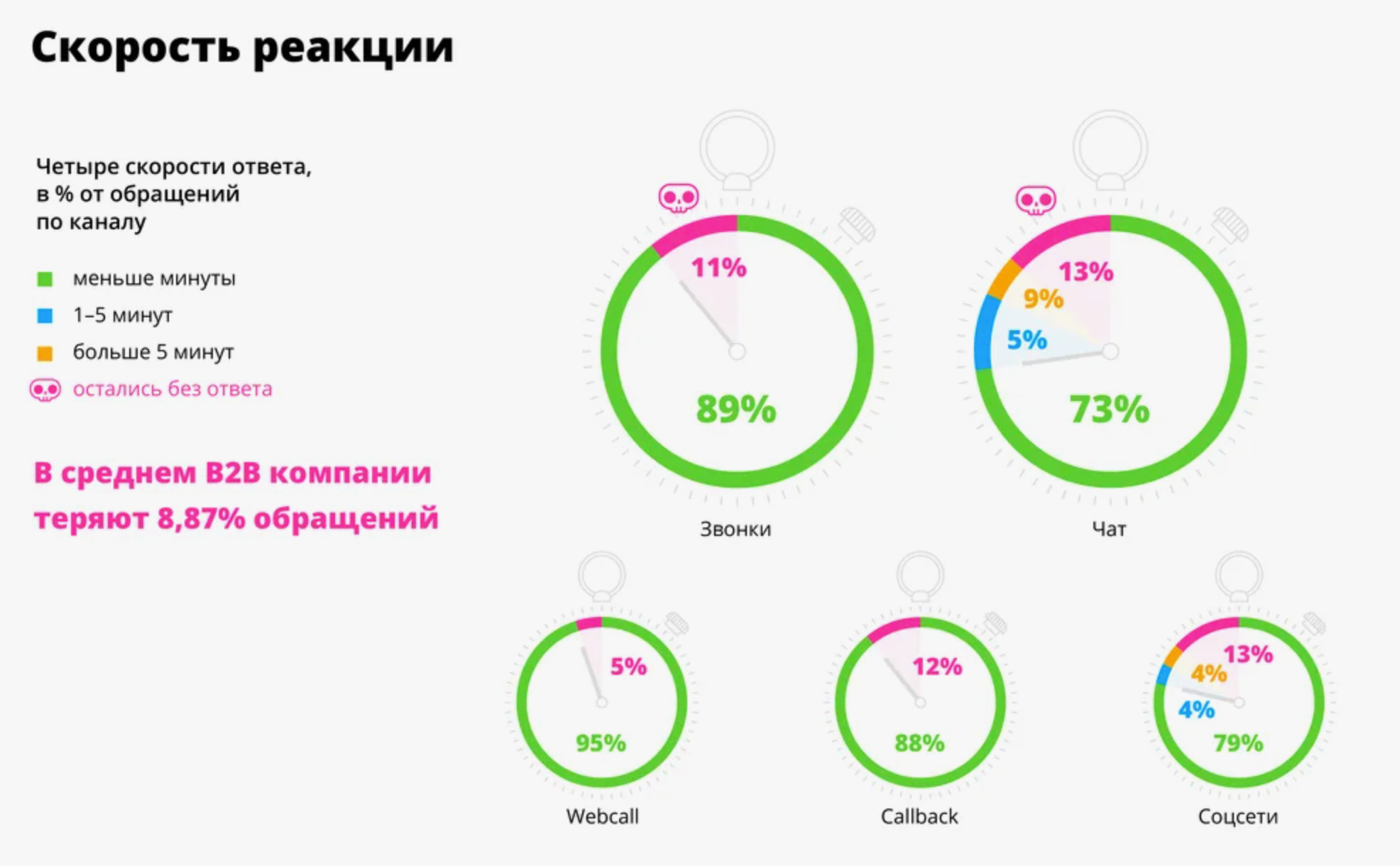
 Списки, множества или другие изменяемые типы нельзя использовать как ключи.
Списки, множества или другие изменяемые типы нельзя использовать как ключи. .
.